The Magnet Forensics Weekly CTF has been running since October and sets one question each week using an image that changes each month. The October questions were based on an Android filesystem dump, and November’s related to a compromised Hadoop cluster built on Ubuntu Linux. The December challenges return to more familiar territory for me – Windows memory analysis!
These questions use the memory image from the Magnet Virtual Summit 2020, which I first examined during the MVS CTF earlier this year. You can find the rest of my Magnet Weekly CTF write-ups here.
We have reached the final challenge of the #MagnetWeeklyCTF and this week the questions were set by Tarah Melton.
Part 1 (30 points)
What is the PID of the application where you might learn “how hackers hack, and how to stop them”?
Format: #### Warning: Only 1 attempt allowed!
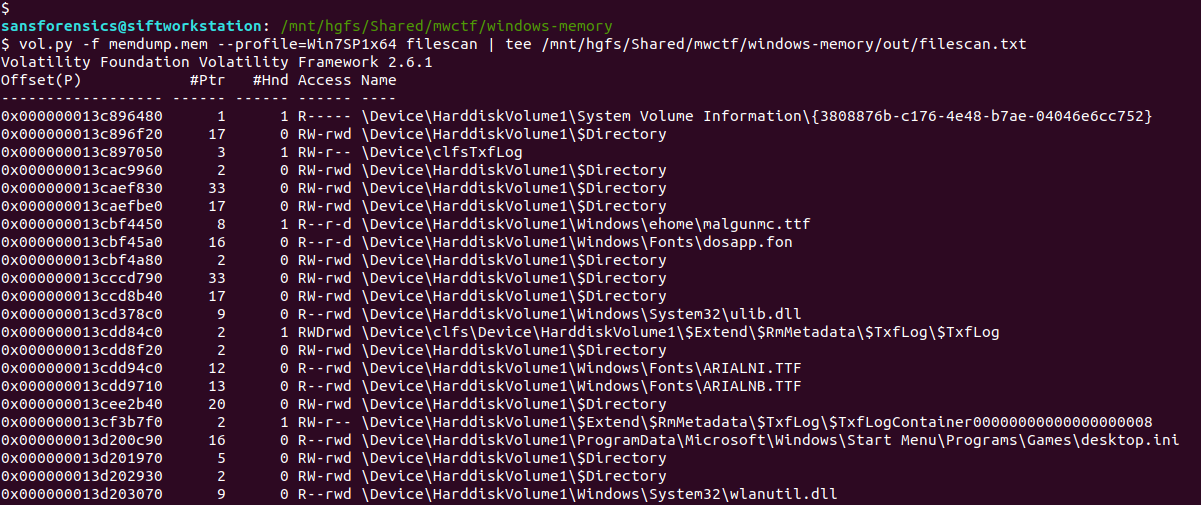
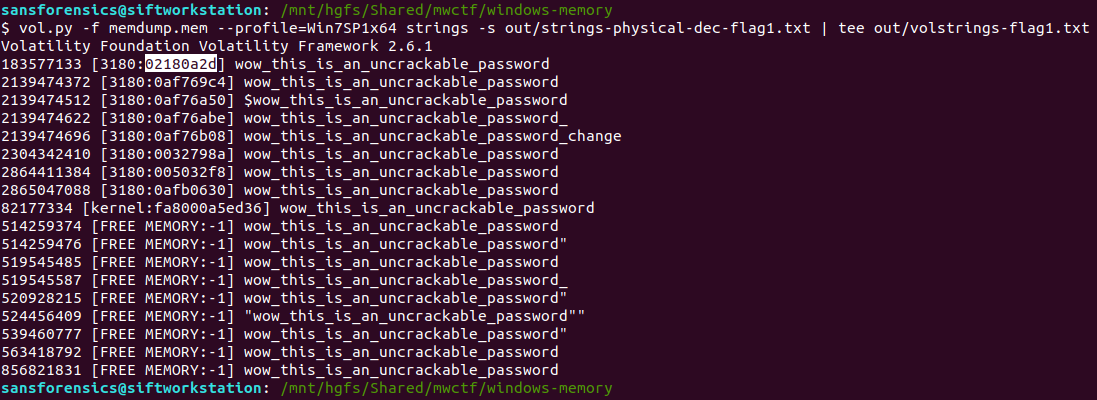
Ok, we are trying to link a particular string to a Process ID. I started by extracting the strings from the entire memory image then using a case-insensitive grep search to get a better idea of what we might be looking for.
strings memdump.mem | grep -i "how hackers hack, and how to stop them"

The text surrounding the match looks like HTML so any of the Internet Explorer or Chrome browser processes are likely candidates, but given the number of them I don’t want to dump each process memory and search manually. Instead, now that we know exactly what to look for, we can throw the yarascan plugin at the image and check the Process ID associated with the matching section of memory. Easy.
vol.py -f memdump.mem --profile=Win7SP1x64 yarascan -Y "How Hackers Hack, and How To Stop Them"

Ok, not a great start. Volatility as installed on the pre-built Ubuntu 18.04 SANS SIFT VM throws an exception because of conflicting use of the -C option in the malfind plugin:
Volatility Foundation Volatility Framework 2.6.1
Traceback (most recent call last):
File "/usr/local/bin/vol.py", line 192, in <module>
main()
File "/usr/local/bin/vol.py", line 174, in main
command = cmds[module](config)
File "/usr/local/lib/python2.7/dist-packages/volatility/plugins/malware/malfind.py", line 190, in __init__
help = 'Make the search case insensitive')
File "/usr/local/lib/python2.7/dist-packages/volatility/conf.py", line 363, in add_option
self.optparser.add_option("-{0}".format(short_option), "--{0}".format(option), **args)
File "/usr/lib/python2.7/optparse.py", line 1021, in add_option
self._check_conflict(option)
File "/usr/lib/python2.7/optparse.py", line 996, in _check_conflict
option)
optparse.OptionConflictError: option -C/--case: conflicting option string(s): -C
Fixing the malfind and yarascan Volatility plugins on SIFT 18.04
Luckily I’m not the first person to run into this problem, and an issue submitted to the SIFT github repository contains a workaround:
Make a backup of the malfind.py source file, which in my SIFT VM was located:
/usr/local/lib/python2.7/dist-packages/volatility/plugins/malware/malfind.py
Then open the original file for editing and change the short_option at line 189. The original conflicting option is C (upper-case); I changed this to c (lower-case), as shown below:
config.add_option("CASE", short_option = 'c', default = False, action = 'store_true',
I also had to change the short_option at line 195. The original option Y (upper-case) caused another conflict, so I changed this to U (upper-case), as below:
config.add_option('YARA-RULES', short_option = 'U', default = None,
Now, with those minor changes in place, we can get back to the challenge. Using the modified yarascan plugin, we search for the correctly-capitalised version of the string.
vol.py -f memdump.mem --profile=Win7SP1x64 yarascan -U "How Hackers Hack, and How To Stop Them"

The yarascan plugin finds our string in three different locations, but all within an Internet Explorer process – PID 4480.
Flag (Part 1)
4480
Part 2 (20 points)
What is the product version of the application from Part 1?
XX.XX.XXXX.XXXXX
Part two asks for the version of Internet Explorer that was used. Microsoft suggest a few options to check Internet Explorer release versions; I started by checking the following key in the SOFTWARE registry hive.
grep -E "^Virtual|(SOFTWARE)" out/hivelist.txt vol.py -f memdump.mem --profile=Win7SP1x64 printkey -o 0xfffff8a0002c9010 -K "Microsoft\Internet Explorer"

We are particularly interested in the value of srcVersion – 11.0.9600.18860 – but this answer was not accepted. Curious. Maybe the Version value – 9.11.9600.18860 – but again, this was not accepted. I noticed that neither of those strings fit the format hint provided in the question, and reading the Microsoft documentation again I saw that 00 version numbers could be truncated to a single 0. Padding the srcVersion value out to 11.00.9600.18860 might be the answer? No.
Time for a different approach. I used the procdump plugin to dump the process executable from memory, then used exiftool to examine the binary metadata. Sure enough, there was a specific Product Version value.
vol.py -f memdump.mem --profile=Win7SP1x64 procdump -p 4480 -D . exiftool -ProductVersion executable.4480.exe

Reading the question properly helps!
Flag (Part 2)
11.00.9600.18858
That is the end of the Magnet Weekly CTF, at least for 2020. A big “thank you” to everyone involved in setting-up and running the challenge, and to all the other participants who wrote-up and published their solutions each week!